나는 책임이 있다 정보 링크접속 서비스는 최근 1000만 MAU를 돌파했다.
그런데 오늘은 MAU가 500만이었을 때 발생한 이슈에 대해 말씀드리려고 합니다.
다음 사람들을 읽으면 더 많은 것을 얻을 수 있습니다.
- 현재 트래픽이 증가하고 있지만 여기서 무엇을 개선해야 할지 모르겠습니다.
- 곧 트래픽이 증가할 것으로 예상되지만 무엇을 준비해야 할지 고민이신 분들은

폭발할 때라고 생각합니까?
그런 말을 많이 하던 때가 있었다. 그 전에 제가 운영하는 Infofrink의 기능과 활용 사례에 대해 말씀드려야 할 것 같습니다.
- 사용자는 단일 페이지(방문자 페이지)에 표시할 내용을 입력합니다.
- 이용자는 인스타그램 등의 프로필 영역에서 (방문자 페이지)에 대한 링크를 등록합니다.
- 사용자는 Instagram에서 “참여하려면 바이오 링크를 클릭”하도록 권장됩니다.
인스타그램 사용자들이 사용하는 서비스인 만큼 영향력 있는 사용자들이 인스타그램에 링크 클릭을 유도하는 글을 올리면 의외로 서버가 붐비는 경우가 많다. (이런 상황에 대비하자고 하시는 분들도 계셨는데 그날은 항상 서버가 터져버렸습니다. ㅠㅠ) 그리고 그 당시에는 많은 트래픽이있었습니다.
그러나 문제는 비교적 명확했습니다.
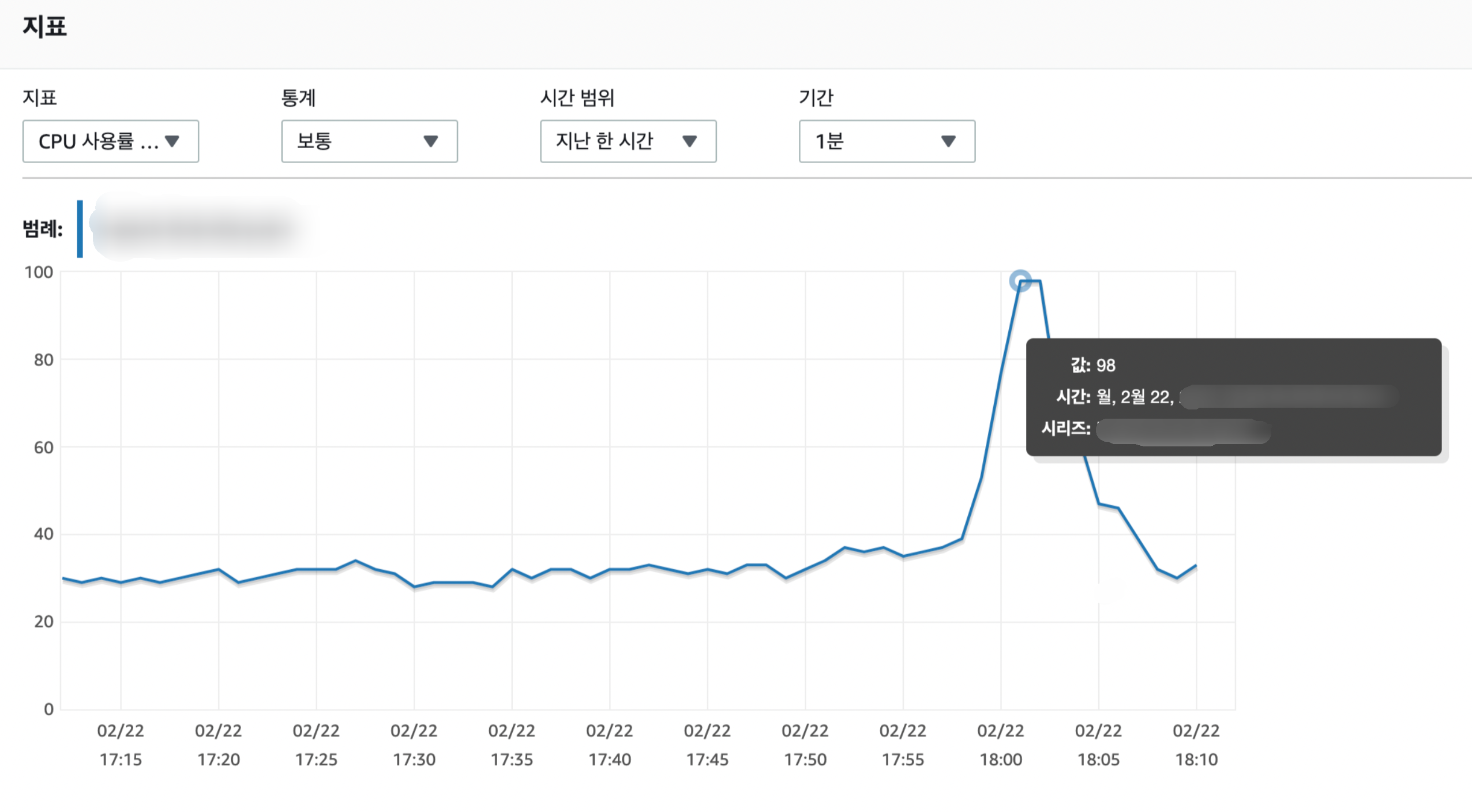
모든 부하가 RDS에 쏟아졌습니다.
한편, 클라이언트와 API 서버는 평화롭게 문제가 없었습니다.
이 시점에서 서버 폭발의 패턴은 상당히 일관되었습니다.
1. 인플루언서가 Instagram에 새로운 피드나 스토리를 게시합니다.
2. 해당 인플루언서의 팔로워는 프로필 링크를 클릭하여 이벤트에 직접 참여합니다.
3. 프로필 링크로 등록한 저희 서비스에 갑자기 부하가 가해집니다.
그래서 항상 RDS 모니터링과 관련된 알림이 Slack에 전달된다면 RDS를 급히 확장할 뿐만 아니라 얼마나 많은 사람들이 GA에 연결되어 있고 어떤 인플루언서가 많은 트래픽을 생성하고 있는지 확인합니다. 그리고 반대로 인플루언서의 인스타그램에 들어가게 되면 게시물을 올리거나 그 게시물 내에서 이벤트를 진행하는 경우가 많습니다.
이 상황에서 어떻게 하시겠습니까?
서버를 확장해야 합니까?
사실 이 사태가 일어나기 전까지는 “가능하면 조금 더 지출하고 우리가 해야 할 사업에 집중하자”는 공감대가 있었다.
하지만 단순히 서버를 증설하는 것만으로 이러한 상황을 해결할 수 있다고 말하기는 어려웠습니다.
그 이유는 다음과 같습니다.
- 트래픽이 얼마나 증가할지 모르겠습니다.
- 트래픽이 증가하는 동안 용량을 추가하기에는 이미 너무 늦었습니다.
- 대부분의 트래픽과 피크 트래픽 사이의 격차는 매우 큽니다.
이 때문에 비효율적인 RDS 확장에 동의할 수 없었습니다.
단순한 비용 외에도 확장을 위한 노력도 비효율적이었습니다.
서버 확장 대신 캐싱
사실 이것보다 훨씬 간단한 해결책이 있었습니다.
그것은 단지 쿼리 결과를 캐싱하는 것입니다.
(너무 쉬운가요? ㅎㅎ)
왜 캐싱해야 합니까?
서비스의 아이덴티티를 생각해보면 너무나 당연하고 단순하다.
- 인플루언서에 의한 콘텐츠 변경이 빈번하지 않습니다.
- 팔로워(방문자 페이지)의 첫 번째 액세스 요청은 읽기 요청입니다.
따라서 이것은 꽤 오랫동안 캐시될 수 있고 자주 변경되지 않는 정보이므로 변경될 때마다 이 정보를 캐시하도록 선택했습니다.
다른 API가 이미 Redis를 통해 가져온 정보를 캐싱하고 있었기 때문에 어려운 생각도 아니었습니다.
캐싱 구조에 대해 여러 가지 구조를 고려했지만 가장 간단한 키-값 구조로 결정했습니다.
각 사용자가 가지고 있는 pk를 키로 사용합니다.
이 과정을 이미지로 표현하면 다음과 같이 표현할 수 있습니다.
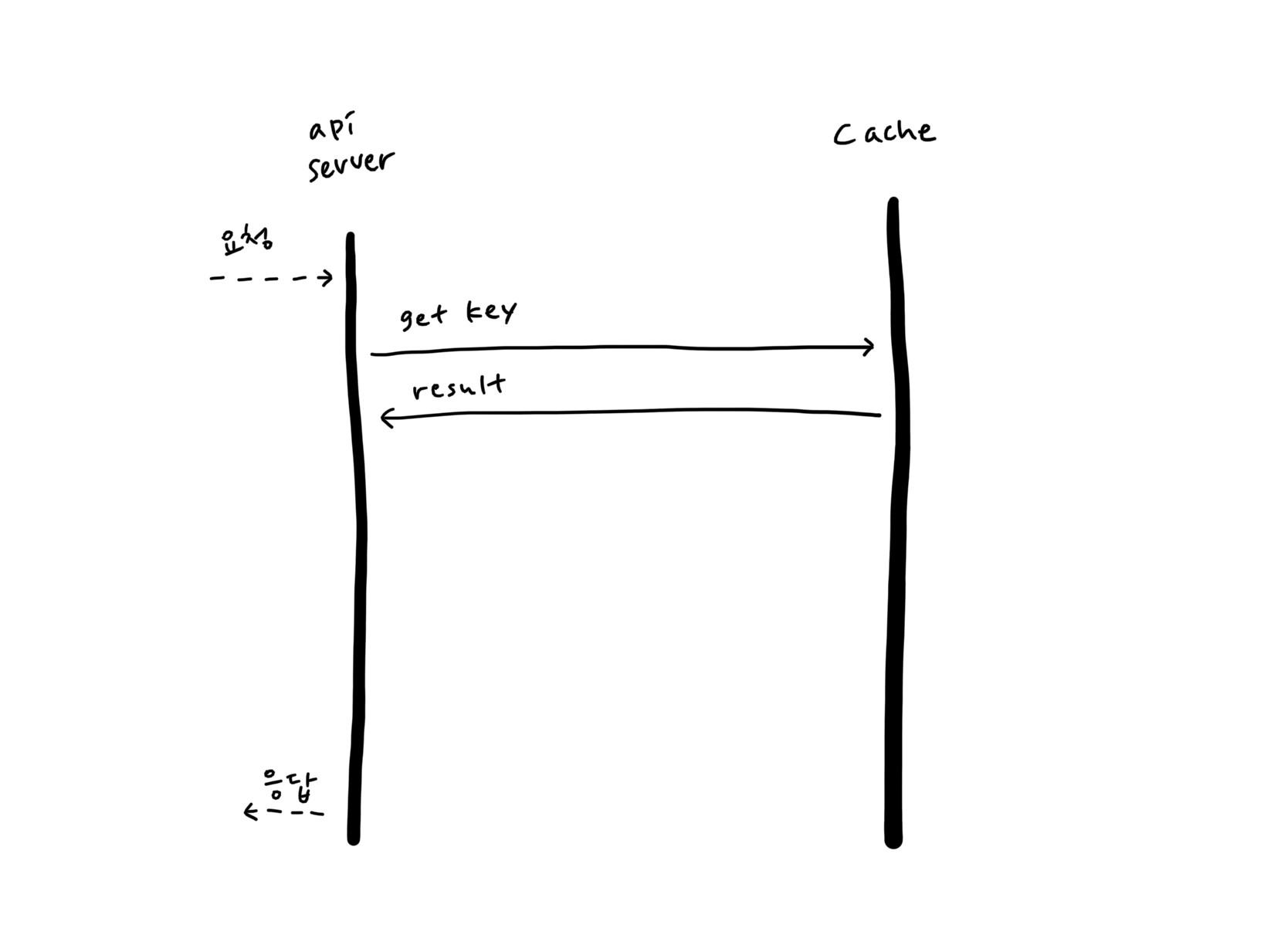
먼저 캐시를 검색하여 키 값이 있으면 응답으로 보낼 수 있습니다.
하지만 방문자 페이지의 속도를 높이기 위해 모든 사용자에게 캐시 데이터를 생성하는 것은 비효율적이라고 생각했기 때문에 인위적으로 캐시를 생성하고 싶지 않았습니다. 그렇다면 캐시가 없는 사용자를 위한 캐시 데이터는 누가, 언제 생성할까요?
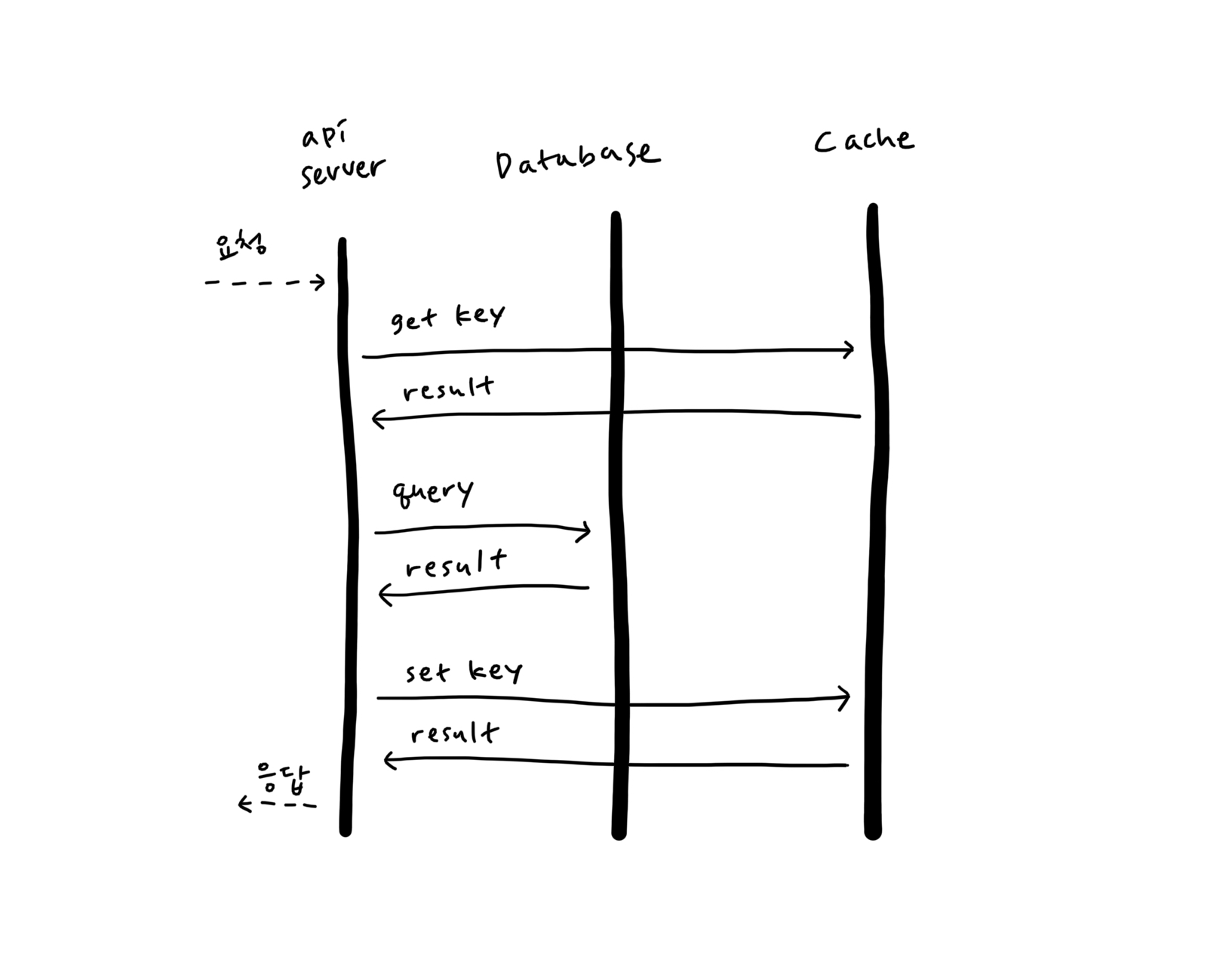
이 데이터에 처음 액세스하는 모든 사람이 조회할 수 있도록 했습니다.
캐시된 데이터가 없으면 데이터베이스를 쿼리합니다.
이미 알고 있었지만 정말 단순한 구조였습니다.
변경해야 할 코드가 몇 줄에 불과해 당일 QA를 거쳐 배포하기로 했다.
결과?

꽤 성공적이었습니다.
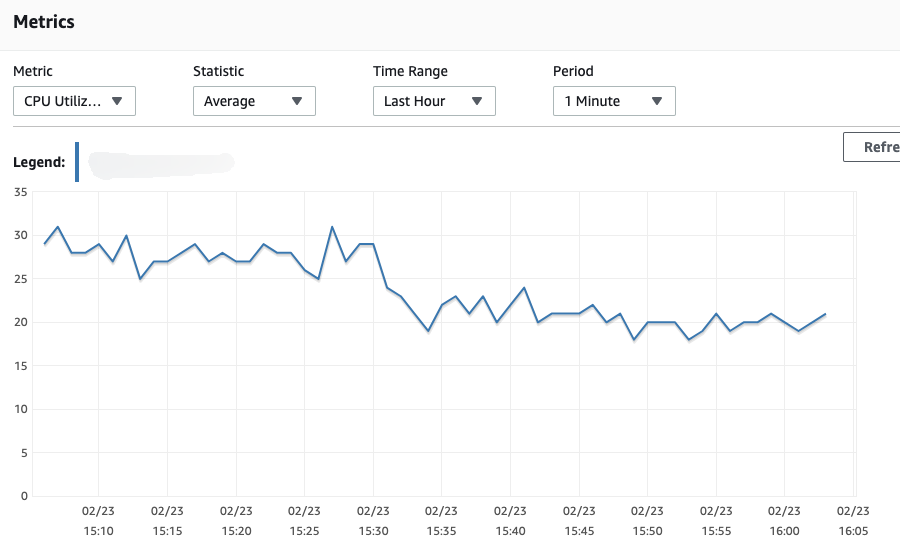
첫 번째 데이터베이스 사용량약 1/3로 줄었습니다.
기존 평균 사용량은 28%였지만 8% 가까이 줄었고 향후 데이터베이스 규모를 줄일 수 있는 계기가 됐다.
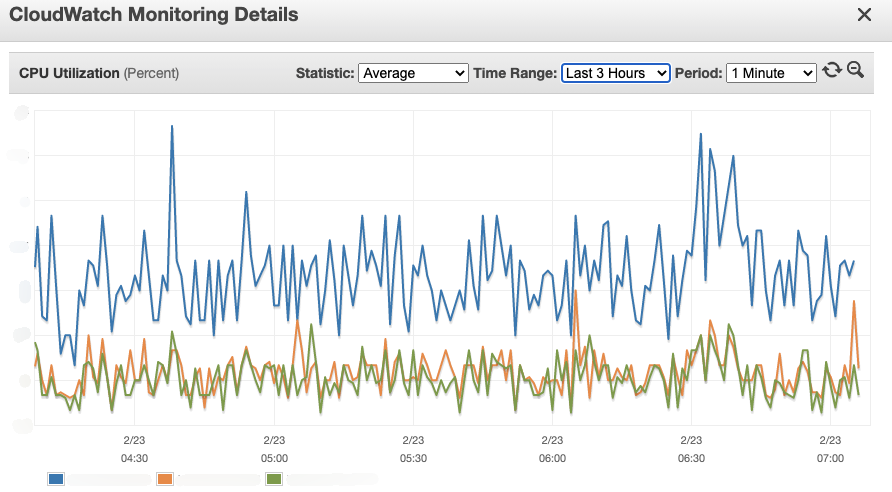
그동안 레디스 사용량올라갔지만 크게 눈에 띄지 않았다.
오랫동안 기다려온 API 요청 비율반면에 교통 체증에서는 몇 초가 걸렸습니다.
10ms~20ms로 줄일 수 있었습니다.
쓰기를 끝내다
캐싱 외에도 속도를 높이거나 효율적인 운영을 위해 다양한 시도가 있어왔다.
다음에는 다른 주제로 포스팅하겠습니다. (피드백은 언제나 환영입니다 🙂 )